Planning
Text
ชื่อหัวข้อที่จะนำเสนอ
- Hash Function vs Compression Algorithm
โครงสร้างของเนื้อหา
- จำนวนหัวข้อทั้งหมดที่จะนำเสนอ
- 2 หัวข้อ
- แต่ละหัวข้อจะนำเสนออะไร
- หัวข้อที่ 1 : เกริ่นนำ
- หัวข้อที่ 2 : อธิบายความแตกต่างระหว่าง Hash Function และ Compression Algorithm
- เปรียบเทียบในด้านการนำไปใช้งาน
- เปรียบเทียบในด้านคุณสมบัติเฉพาะ - Reference : อ้างอิงจากที่เรียนกันภายใน Thursday Community Calls : Thursday Community Calls : ทำความเข้าใจ Hash Function และการใช้งาน - YouTube
Graphic
เสนอไอเดียสำหรับออกแบบกราฟฟิค
รูปแบบของกราฟฟิคที่จะนำเสนอ
โครงสร้างของกราฟฟิค
- จำนวน Page ที่จะนำเสนอ
- …รูป
- แต่ละ Page เป็นรูปแบบอย่างไร
- รูปที่ 1 :
- รูปที่ 2 :
- รูปที่ 3 :
คำถามที่รบกวนให้ Reviewer ช่วยตอบค่ะ
1. ต้องการรู้ประเด็นไหนเพิ่มเติมไหม เพราะอะไร
2. คิดว่าเรียงลำดับการนำเสนอได้ดีรึยัง ถ้าไม่ดี มีไอเดียอย่างไร
3. มีประเด็นไหนควรตัดทิ้งไหม เพราะอะไร
Content

จากบทความที่ผ่านมาเราได้มีการพูดถึง Hash Function กับ Compression Algorithm กันไป หลาย ๆ คนจะเข้าใจว่าทั้ง 2 ขั้นตอนวิธีนี้มีความคล้ายกันในเรื่องของการเปลี่ยนแปลงขนาดข้อมูลหรืออาจจะคิดว่าทั้ง 2 ขั้นตอนวิธีนี้เหมือนกันไปเลยก็ได้ ดังนั้นในบทความนี้เราจะเปรียบเทียบให้เห็นถึงความแตกต่างของทั้ง 2 ขั้นตอนวิธี ในแง่มุมของคุณสมบัติเฉพาะ และการนำไปใช้งาน
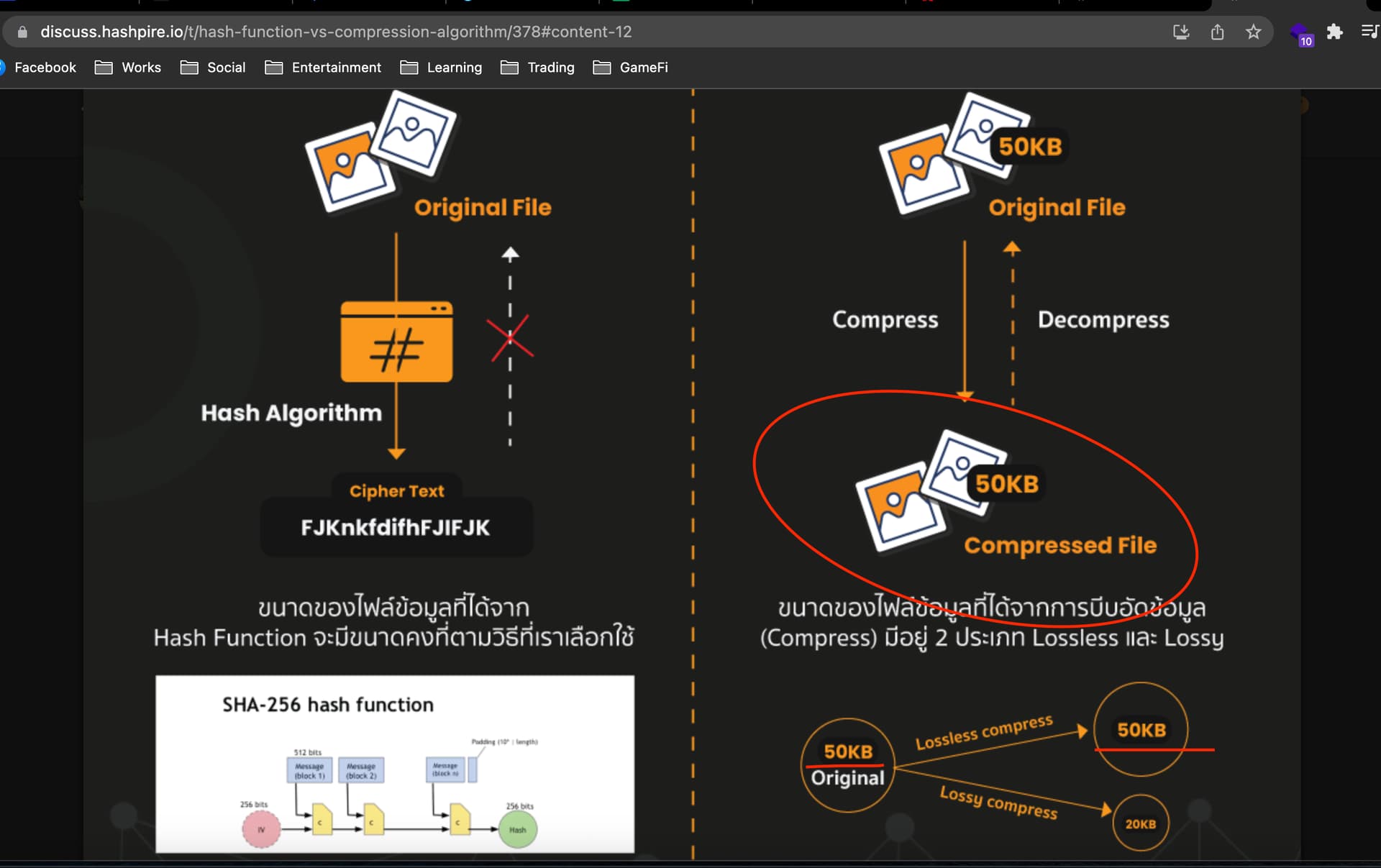
Compression Algorithm เป็นขั้นตอนวิธีการบีบอัดข้อมูลให้มีขนาดเล็กลง โดยที่เรายังสามารถทำให้กลับมาเป็นเหมือนเดิมได้ มีจุดประสงค์เพื่อลดพื้นที่ในการจัดเก็บข้อมูลหรือทำให้การถ่ายโอนข้อมูลไปยังคอมพิวเตอร์เครื่องอื่นทำได้รวดเร็วขึ้น นอกจากนั้นตัว Compression ยังสามารถแบ่งได้เป็น 2 ประเภท คือ Lossless Compression เป็นการบีบอัดข้อมูลที่เมื่อขยายข้อมูลกลับมา จะได้ข้อมูลที่มีความสมบูรณ์เหมือนต้นฉบับ ส่วนอีกแบบก็คือ Lossy Compression เป็นการบีบอัดข้อมูลที่มีการสูญเสียข้อมูลบางอย่างออกไป เพื่อให้ได้ขนาดที่เล็กมาก ๆ เมื่อขยายข้อมูลกลับมา ข้อมูลที่ได้จะไม่เหมือนกับต้นฉบับ เช่น รูปภาพที่อาจจะมีความคมชัดน้อยลง
ในขณะที่ Hash Function เป็นขั้นตอนวิธีการแปลงข้อมูลที่ไม่สามารถทำให้กลับไปเป็นรูปแบบเดิมได้อีก มีจุดประสงค์ในการใช้งานหลากหลายรูปแบบ เช่น เพื่อตรวจสอบความสมบูรณ์ของข้อมูลโดยตรวจจับการเปลี่ยนแปลงแก้ไขข้อมูล เป็นต้น และที่สำคัญคือ ขนาดของข้อมูลที่ได้จาก Hash Function จะมีขนาดคงที่ตามขั้นตอนวิธีที่เราเลือกใช้ ไม่ว่าข้อมูลต้นฉบับจะมีขนาดใหญ่หรือเล็กเท่าใด เช่น SHA-256 เมื่อข้อมูลต้นฉบับผ่านการ Hash แล้วผลลัพธ์ที่ได้จะมีขนาด 256 bit เท่านั้น
Reference